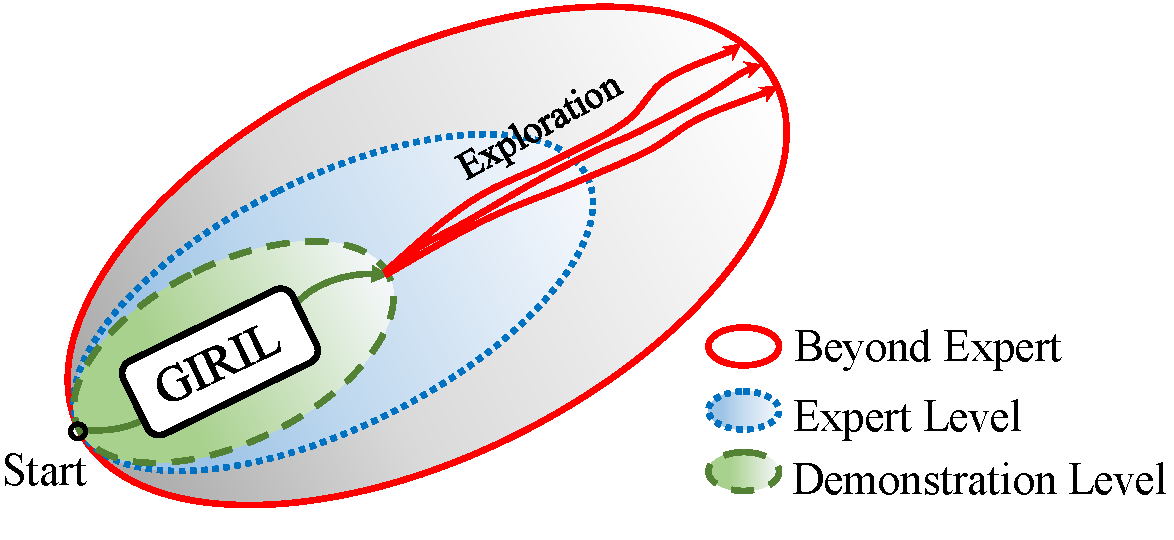
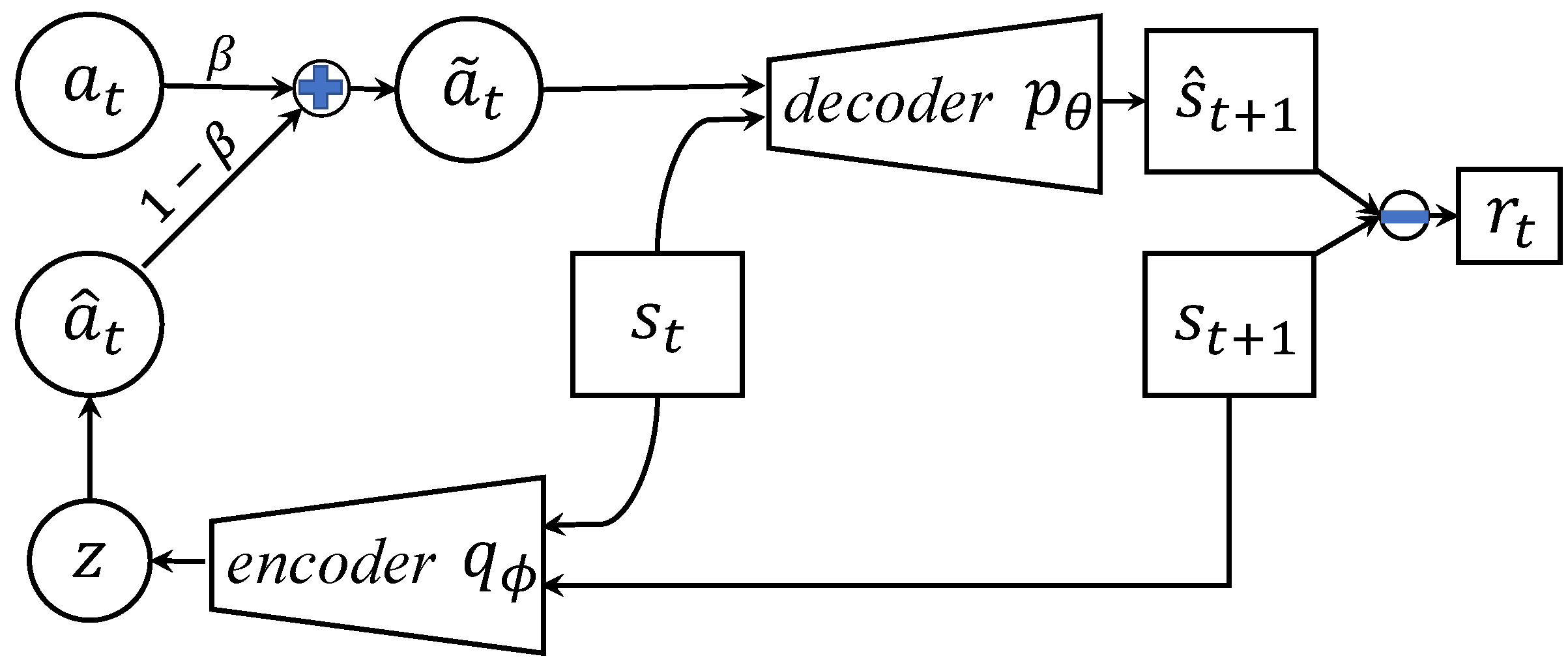
GIRIL operates by reward inference and policy optimization, and includes a novel generative intrinsic reward learning (GIRL) module based on a generative model. We chose variational autoencoder (VAE) (Kingma & Welling, 2013) as our model base. It operates by modeling the forward dynamics as a conditional decoder and the backward dynamics as a conditional encoder. The decoder learns to generate diverse future states from the action conditioned on the current state. Accordingly, the encoder learns to encode the future state back to the action latent variable (conditioned on the current state). In this way, our generative model performs better forward state transition and backward action encoding, which improves its dynamics modeling ability in the environment. Our model generates a family of intrinsic rewards, which enables the agent to do sampling-based selfsupervised exploration in the environment, which is the key to better-than-expert performance.
Demo Videos
Demo videos of the environments investigated in the paper. We show that agents are able to outperform the expert performance by imitation learning from only a one-life demonstration.
